Advanced Database Management System MCA Paper Dec 2020
- Subject Code: - PGCA 1953
- Subject Name: - Advanced Database Management System
- Date of Examination: - December 2020
- Class: - MCA 1st
Instructions to Candidates
- Section A is Compulsory consisting of TEN questions carrying TWO marks each.
- Section B & C have FOUR questions each.
- Attempt any FIVE questions from SECTION B & C carrying TEN marks each.
- Select at least TWO questions from SECTION B & C
- What do you mean by redundancy & how can it be avoided?
- What is the difference between the strong entity and weak entity set?
- Discuss the four data allocation strategies in the case of Distributed Databases.
- What is Relational Calculus?
- What is a NoSQL database? List any 2 NoSQL databases.
- Differentiate between a super key and a candidate key.
- What is Multivalve dependence?
- What is Spatial Database?
- Differentiate between 2-tier and 3-tier client-server architecture of database systems.
- List the different activities of a Database Administrator.
- Define Relational Algebra. Explain the Fundamental operations of Relational Algebra with the help of examples.
- What are the Integrity Constraints? Explain different Integrity Constraints in detail.
- What is Normalization? Discuss the role of normalization in database design. Explain in detail the first three forms of normalization with suitable examples.
- What is Timestamp? How does the system generate timestamps? Discuss the timestamp ordering protocol for concurrency control.
- What is a Parallel Database? What are the Benefits of Parallel Database?
- Explain concurrency control in the distributed database.
- What is Multidatabase System? Describe its reference architecture.
- What are the advantages of a distributed database management system over a centralized DBMS?
- Explain Concurrency Control and Recovery in Distributed Databases.
- Discuss in detail XML DTDs and their types with suitable examples.
Answers: -
Section A
Q1. What do you mean by redundancy & how can it be avoided?
- Deletion of unused data: You moved your customer data into a new database but forgot to delete the same from the old one. To reduce data redundancy, always delete databases that are no longer required.
- Design your Database: With in-house applications that read from databases, you can design your database’s architecture the right way. The relational databases will ensure that you have common fields and allow you to link up tables and match records. This will make it easier for you to figure out repetition and remove it.
- Normalize Database: It is a process in which data is efficiently organized in a database so that duplication can be avoided. It ensures that the data across all the records provide a similar look and can be read in a particular manner. With data normalization, you can standardize data fields, including customer names, contact information, and address. This will help you delete, update, and insert any information with ease.
Q2. What is the difference between the strong entity and weak entity set?

Q3. Discuss the four data allocation strategies in the case of Distributed Databases.
- data partitioning - Database partitioning is the backbone of modern distributed database management systems. It is a process of dividing a large dataset into several small partitions placed on different machines. In other words, It is a way of partitioning data like tables, indexes, and index-organized tables into smaller pieces so that data can be easily accessed and managed.
- data placement - Data placement refers to the problem of deciding how to assign data items to nodes in a distributed system to optimize one or several of a number of performance criteria such as reducing network congestion, improving load balancing, among others.
- data replication - Data replication is the process of making multiple copies of data and storing them at different locations for backup purposes, fault tolerance and to improve their overall accessibility across a network.
- data allocation - Allocation of data is one of the key design issues of distributed database. ... The main objective of a data allocation in distributed database is to place the data fragments at different sites in such a way, so that the total data transfer cost can be minimized while executing a set of queries.
Q4. What is Relational Calculus?
- Tuple Relational Calculus (TRC) - The tuple relational calculus is specified to select the tuples in a relation. In TRC, filtering variable uses the tuples of a relation. The result of the relation can have one or more tuples.
- Domain Relational Calculus (DRC) - The second form of relation is known as Domain relational calculus. In domain relational calculus, filtering variable uses the domain of attributes. Domain relational calculus uses the same operators as tuple calculus. It uses logical connectives ∧ (and), ∨ (or) and ┓ (not). It uses Existential (∃) and Universal Quantifiers (∀) to bind the variable.
Q5. What is a NoSQL database? List any 2 NoSQL databases.
- MongoDB
- Cassandra
- ElasticSearch
- Amazon DynamoDB
- HBase
Q6. Differentiate between a super key and a candidate key.

Q7. What is Multivalve dependence?
Ans: - Multivalued Dependency exists in a relation when two attributes depend on the third attribute but independent to each other. It is a full constraint between two sets of attributes in a relation. It plays a vital role in 4NF. Multivalued Dependencies are also referred to as tuple generating dependencies.
Example: The relation student consists of three attributes student_id, Name, Course.

In the above relation, Name and Course are two independent attributes in itself, but both are dependent on student_id. In this case, these two attributes are multivalued dependent on student_id. Following are the representation of these dependencies:
Q8. What is Spatial Database?
Ans: - Spatial data is associated with geographic locations such as cities, towns etc. A spatial database is optimized to store and query data representing objects. These are the objects which are defined in a geometric space.
- It is a database system
- It offers spatial data types (SDTs) in its data model and query language.
- It supports spatial data types in its implementation, providing at least spatial indexing and efficient algorithms for spatial join.
Q9. Differentiate between 2-tier and 3-tier client-server architecture of database systems.
Q10. List the different activities of a Database Administrator.
Ans: -- Decides hardware – They decides economical hardware, based upon cost, performance and efficiency of hardware, and best suits organization. It is hardware which is interface between end users and database.
- Manages data integrity and security – Data integrity need to be checked and managed accurately as it protects and restricts data from unauthorized use. DBA eyes on relationship within data to maintain data integrity.
- Database design – DBA is held responsible and accountable for logical, physical design, external model design, and integrity and security control.
- Database implementation – DBA implements DBMS and checks database loading at time of its implementation.
- Query processing performance – DBA enhances query processing by improving their speed, performance and accuracy.
- Tuning Database Performance – If user is not able to get data speedily and accurately then it may loss organization business. So by tuning SQL commands DBA can enhance performance of database.
Section B
Q1. Define Relational Algebra. Explain the Fundamental operations of Relational Algebra with the help of examples.
Fundamental operations of Relational Algebra
- Select Operator (σ) - Select Operator is denoted by sigma (σ) and it is used to find the tuples (or rows) in a relation (or table) which satisfy the given condition. If you understand little bit of SQL then you can think of it as a where clause in SQL, which is used for the same purpose.
- Syntax of Select Operator (σ)

- Select Operator (σ) Example

- Query:
- Output:

- Project Operator (∏) - Project operator is denoted by ∏ symbol and it is used to select desired columns (or attributes) from a table (or relation). Project operator in relational algebra is similar to the Select statement in SQL.
- Syntax of Project Operator (∏)

- Project Operator (∏) Example - In this example, we have a table CUSTOMER with three columns, we want to fetch only two columns of the table, which we can do with the help of Project Operator ∏.

- Query:

- Output:

- Union Operator (∪) - Union operator is denoted by ∪ symbol and it is used to select all the rows (tuples) from two tables (relations). Lets discuss union operator a bit more. Lets say we have two relations R1 and R2 both have same columns and we want to select all the tuples(rows) from these relations then we can apply the union operator on these relations.
- Syntax of Union Operator (∪)
- Union Operator (∪) Example
- Table 1: COURSE

- Table 2: STUDENT

- Query:

- Output:

- Note: As you can see there are no duplicate names present in the output even though we had few common names in both the tables, also in the COURSE table we had the duplicate name itself.
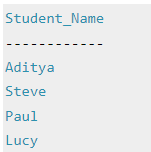
- Intersection Operator (∩) - Intersection operator is denoted by ∩ symbol and it is used to select common rows (tuples) from two tables (relations). Lets say we have two relations R1 and R2 both have same columns and we want to select all those tuples(rows) that are present in both the relations, then in that case we can apply intersection operation on these two relations R1 ∩ R2.
- Note: Only those rows that are present in both the tables will appear in the result set.
- Syntax of Intersection Operator (∩)
- Intersection Operator (∩) Example
- Lets take the same example that we have taken above.
- Table 1: COURSE

- Table 2: STUDENT

- Query:

- Output:
- Set Difference (-) - Set Difference is denoted by – symbol. Lets say we have two relations R1 and R2 and we want to select all those tuples(rows) that are present in Relation R1 but not present in Relation R2, this can be done using Set difference R1 – R2.
- Syntax of Set Difference (-)
- Set Difference (-) Example - Lets take the same tables COURSE and STUDENT that we have seen above.
- Query: Lets write a query to select those student names that are present in STUDENT table but not present in COURSE table.

- Output:

- Cartesian product (X) - Cartesian Product is denoted by X symbol. Lets say we have two relations R1 and R2 then the cartesian product of these two relations (R1 X R2) would combine each tuple of first relation R1 with the each tuple of second relation R2. I know it sounds confusing but once we take an example of this, you will be able to understand this.
- Syntax of Cartesian product (X)
- Cartesian product (X) Example
- Table 1: R

- Table 2: S

- Query: Lets find the cartesian product of table R and S.R X S
- Output:

- Note: The number of rows in the output will always be the cross product of number of rows in each table. In our example table 1 has 3 rows and table 2 has 3 rows so the output has 3×3 = 9 rows.
- Rename (ρ) - Rename (ρ) operation can be used to rename a relation or an attribute of a relation.
- Rename (ρ) Syntax:

- Rename (ρ) Example - Lets say we have a table customer, we are fetching customer names and we are renaming the resulted relation to CUST_NAMES.
- Table: CUSTOMER

- Query:

- Output:

Q2. What are the Integrity Constraints? Explain different Integrity Constraints in detail.
- Integrity constraints are a set of rules. It is used to maintain the quality of information.
- Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected.
- Thus, integrity constraint is used to guard against accidental damage to the database.

- Domain constraints - Domain constraints can be defined as the definition of a valid set of values for an attribute. The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain.
- Example:

- Entity integrity constraints - The entity integrity constraint states that primary key value can't be null. This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows. A table can contain a null value other than the primary key field.
- Example:

- Referential Integrity Constraints - A referential integrity constraint is specified between two tables. In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2.
- Example:

- Key constraints - Keys are the entity set that is used to identify an entity within its entity set uniquely. An entity set can have multiple keys, but out of which one key will be the primary key. A primary key can contain a unique and null value in the relational table.
- Example:

Comments
Post a Comment